12.chapter 7 Evaluating Recommender Systems
7 추천 시스템 평가 방법
Evaluating Recommender Systems
~7.3 까지의 내용을 정리하자면 추천시스템도 분류나 회귀와 마찬가지로 성능을 평가한다. 평가 방식에는 user studies, online, offline 세 가지가 있다. 추천시스템에서는 offline 방식이 인기있는 평가 방식이다. offline 방식은 이전의 데이터들을 한 시점을 기준으로 한 데이터셋이기 때문에 다른 알고리즘과 비교해 표준화된 벤치마킹을 위해 사용할 수 있다. 그리고 다양한 도메인의 데이터 셋이기 때문에 구현한 추천시스템 모델을 일반화 테스트 하는데 사용할 수 있다. 그리고 가장 널리쓰이는 추천시스템의 평가의 기준은 정확도이다. 그 외에도 추천된 항목들이 사용자에게 얼마나 다양한지, 새로운지, 확장성이 있는지, 의외성이 있는지 등이 기준이 될 수 있다.
머신러닝 스터디를 하면서 학습했던 내용이 추천시스템의 성능 평가와 연계되었다. 선형대수… 스터디에서 모델의 평가 방법으로 배웠던 내용들과 핸즈온 머신러닝 스터디에서 전체적인 머신러닝 프로젝트 과정을 보고 마지막 단계에서 데이터를 분할하여 학습하고 테스트 하는 과정을 심화로 학습했던것이 도움이 되었다.
7.4 Design Issues in Offline Recommender Evaluation
Offline 방식으로 추천시스템을 평가할 때 주어진 데이터셋을 어떻게 나누어 사용할 것인지에 관한 내용이다.
⭐️ 정확도가 과대적합, 과소적합되지 않게 데이터 셋을 구성하는것이 중요하다.
- training, test set에 같은 specified rating set을 쓰지 않는다.
→ training, test 에 쓸 데이터를 나눈다.(분류나 회귀 모델을 테스트하는 과정가 유사하다. 다른점이라면 추천시스템에서는 entry를 샘플링한다는 점이다.)
- parameter tunning, testing을 위해 같은 data를 쓰지 않는다.
→ parameter tunning은 training의 일부분임을 기억하자.

- training data : training 모델을 만들고 생성하는데 사용한다.
- latent factor model을 예로 들면, rating set(데이터셋)에서 latent factors을 만드는데 training data를 사용한다.
- Validation data : 모델을 선택하고 parameter tunning을 위해 사용한다.
- latent factor model에서 regularization parameters는 validation data에서 정확도를 확인하면서 정할 수 있다.
- Testing data : 위의 과정에서 정해진 final model의 정확도를 테스트하기 위해 사용한다.
- ⭐️ parameter tunning, 모델 선택 과정에서 테스트 데이터를 미리 보는 행위는 금지!
- 테스트 데이터는 이 과정의 끝에서 오직 한번만 사용한다.
7.4.1 Netflix Prize Data Set

- Training Set Excluding prob set : 대부분의 데이터가 training data로 사용된다. 모델을 만들기 위한 데이터다.
- Probe Set : probe set이다. paramater tunning, model-selection을 위한 데이터를 따로 빼두었다. validation data의 역할을 한다.
- Quiz set : quiz set의 평점은 대회 참가자들에게는 공개되는 데이터다. 하지만 학습할 시엔 알 수 없다.
- Test set : 참가자에게 조차도 평점이 공개되지 않는다.
NETFLIX PRIZE - 더 많은 내용을 알고싶으면!
7.4.2 Segmenting the Rating for Training and Testing
실제 데이터가 Netflix Data 처럼 trainig, test 이렇게 나누어져 있진 않다. 그래서 rating metrix의 entry들을 자동으로 나누는 것은 중요하다.
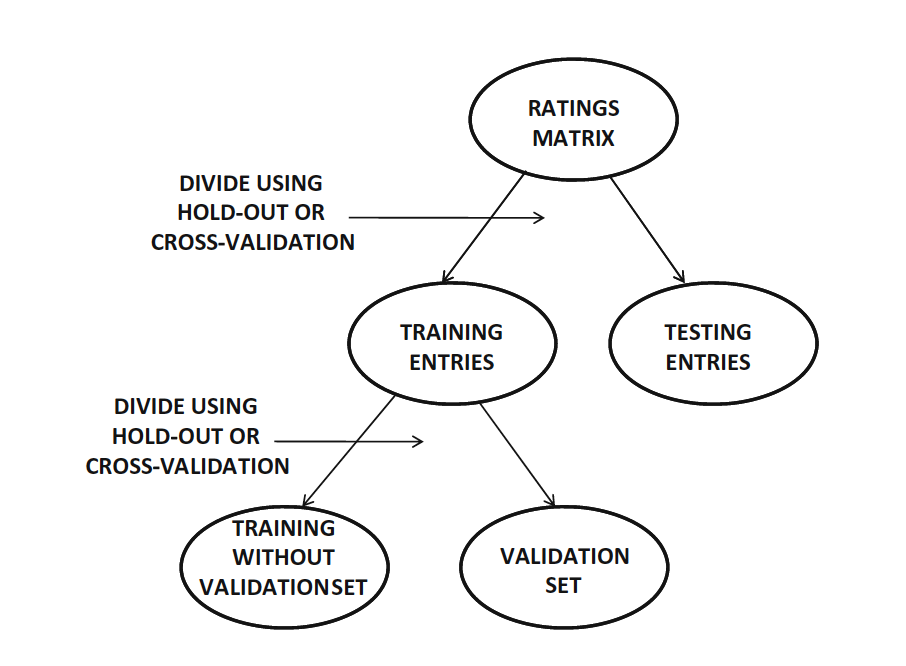
- rating metrix → training , test
- training → validation, 나머지
위와 같이 나누는 방법에는 두 가지가 있다.
7.4.2.1 HOLD-OUT
데이터셋을 나눌 때 데이터를 보지 않고 일부분(hold-out)을 떼어내고 나머지를 training data로 사용한다. 하지만 이 방법은 과소적합 문제가 발생할 수 있다.
- 모든 entry가 training에 사용되지 않는다. 그래서 전체 데이터를 다 사용했을 때 보다 학습이 약할 수 있다.
- 떼어낸 일부분이 나머지보다 평균적으로 높은 평균값을 가진다면 training data에서 학습한 모델을 held-out 된 데이터에 test 해보았을 때 좋지 않은 결과가 나올 수도 있다.
7.4.2.2 CROSS-VALIDATION

5-fold cross validation
보통은 10-fold 방법을 쓴다.
$S$ : rating metrix R에서 특정된 entry들의 집합
$|S| /q$ : q개로 나눈 집합.
1개는 테스트를 위해 사용하고, $(q-1)$개는 training을 위해 사용한다. neighborhood-based collaborative filtering 시스템에 적용하기에 엄청 어렵진 않다.
7.4.3 Classification with Classification Design
추천시스템의 평가 방식을 분류의 평가 방식과 비교했을 때 다른 점은 추천시스템에선 사용 되는 데이터가 entry 기반 이라는 것이다.
7.5 Accuracy Metrics in Offline Evaluation
추천시스템에서 정확도를 평가하는 방식은 두 가지가 있다.
- 추천시스템으로 예측한 rating의 정확도
- ⭐️ 추천시스템으로 추천된 top-k개의 raking의 정확도
주로 2번의 방식이 사용된다. netflix prize competition은 RSME 측정값으로 최종 평가를 했다.
7.5.1 Measuring the Accuracy of Ratings Prediction
$S$ : 알고있는 rating 집합
$E$ : $E \subset S$ test set에서 모델 평가를 위한 set
$r_{uj}$ : $(u,j) \in E$ rating 값
$\hat{r}_{uj}$ : 예측된 값
$e_{uj} = \hat{r_{uj}} - r_{uj}$ : 예측 오류값
-
MSE : MSE 값이 작을 수록 높은 성능의 시스템이다.
$MSE = \frac{\sum_{(u,j) \in E}{e_{uj}}^2}{|E|}$
-
RMSE : 이상치에 민감한 값이다.
$RMSE = \sqrt{\frac{\sum_{(u,j) \in E}{e_{uj}}^2}{|E|}}$
-
MAE
$MAE = \frac{\sum_{(u,j) \in E} |{e_{uj}}|}{|E|}$
-
NRMSE : Normalized RMSE(정규화된 RMSE)
$NRMSE=\frac{RMSE}{r_{max}-r_{min}}$
-
NMAE : Normalized RMSE(정규화된 NAE)
$NMAE=\frac{MAE}{r_{max}-r_{min}}$
NRMSE, NMAE 둘 다 범위가 (0,1)로 직관적인 비교에 유용하다.
7.5.1.1 RMSE vs MAE
RMSE는 outlier나 큰 에러 값에 MAE 보다 더 큰 영향을 받는다. 강력한 예측을 원한다면 RMSE가 적합한 평가 기준이 된다. RMSE의 단점은 평균 에러값을 반영하지 못한다.
7.5.1.2 Impact of the Long Tail
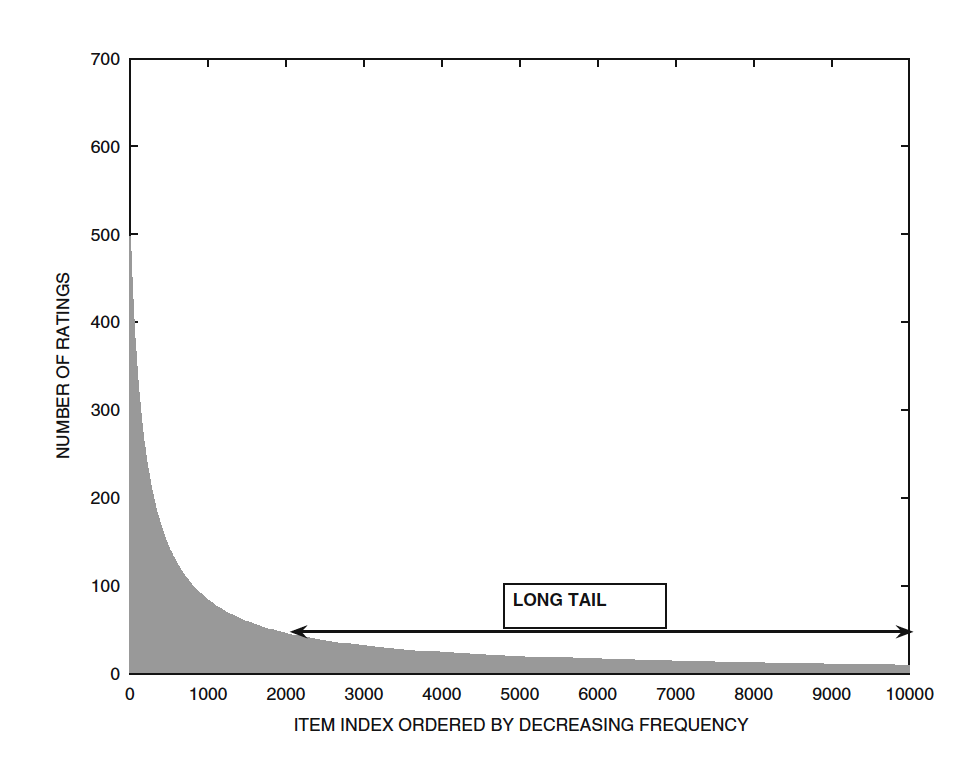
인기가 많은 소수의 아이템들이 많은 rating의 값을 얻는다. 따라서 long-tail에 있는 아이템들에 대한 예측 정확도를 측정하는 방법과 인기있는 소수의 아이템들에 대한 예측 정확도를 평가하는 방법이 달라야 한다.이 문제를 해결하는 방법은 RMSE or MAE를 나누어서 test data에서 계산한 후 가중치를 정해 평균을 내는 것이다.
7.5.2 Evaluating Ranking via Correlation
user-item 조합의 rating 값의 예측 정확도를 평가하는 방법으로는 앞의 방법들을 사용했다. 실제로는 추천시스템은 top-k개의 아이템을 추천하기 때문에 raking의 정확도를 평가하는 것 또한 추천시스템을 평가하는 방법이다. 실제로 rating의 순서가 추천시스템이 예측한 순서와 얼마나 관련있는지를 평가한다.
$I_u$ : hold-out이나 cross-validation으로 나누어져서 평가 점수를 알 수 없는 항목들의 집합
-
Spearman rank correlation coefficient : pearson correlation coefficient 방법과 유사하다.
rating과 user를 한번에 계산할 수 있다. 이 방법의 문제는 동일한 랭크가 있을 때 평가에 있어서 잡음이 생긴다.
-
Kendall rank correlation coefficient : $j,k \in I_i$ 두 아이템간의 순위를 비교해서 연관성을 찾는다.
$\tau_u = \frac{\sum_{j < k} C \left( j,k \right) }{|I_u| \cdot \left( I_u -1 \right)/2 }$
$\tau_u = \frac{일치하는 쌍들의 개수 - 일치하지 않은 쌍들의 개수}{집합 I_u에서 쌍의 수 }$
concordant : 일치하는 쌍들, discordant : 일치하지 않은 쌍들
7.5.3 Evaluation Ranking via Utility
사용자에게 얼마나 유용한 아이템을 랭킹해주었는지를 평가하는 것이다. 이는 사용자의 rating이 높을수록 사용자에게 유용할 것이고, 추천순위에서 상위권에 있는 아이템일수록 사용자에게 유용할 것이라는 것을 기반으로 한다.
$C_u$ : 사용자 $u$의 break-even rating
$max{(r_{uj}-C_u,0)}$ : rating-based utility
$v_j$ : 아이템 $j$의 ranking
$2^{(v_j-1)/\alpha}$: ranking-based utility
-
utility function
$F \left( u,j \right) = \frac{ max \{ r_{uj}-C_u,0 \} }{2^{(v_j-1)/\alpha}}$
- R-score: utility function의 합계
- 추천리스트는 최대 $L$개까지 노출되기 때문에 랭킹 $L$ 이하 레벨은 사용자들에게 utility가 없다.
$R-score \left( u\right) = \sum_{j \in I_u, v_j \lt L} F \left(u,j \right) $
- DCG : Discounted Cumulative Gain
$DCG = \frac{1}{m}\sum_{u=1}^m \sum_{j \in I_u, v_j \lt L} \frac{g_uj}{log_2\left(v_j+1\right)}$
- $log_2{(v_j+1)}$ : 아이템 $j$에 대한 discount factor($v_j$는 ranking 순서값)
- $g_{uj} = 2^{rel_i}-1$ : 사용자 $u$에게 아이템$j$에 대한 utility
- $ rel_{uj} $ : ground-truth relevance(추천 결과들의 관련성)
- $m$ : m명의 사용자 수
- 랭킹 순서에 따라 점점 비중을 줄여가면서(discounted) 관련도를 계산하는 방법이다.
- 랭킹 순서에 대한 로그함수를 분모에 두고, utility를 분자로 두어 하위권으로 갈수록 $rel$ 대시 작은 값을 같게 된다.
- ARHR : average reciprocal hit ratio
- $1/v_j$ : rank-based discount rate
- $r_{uj}$ : item utility $\in {0,1}$이다. 사용자에게 유용한가(1), 유용하지 않은가(0)
- $r_{uj}/v_j$ : 위 둘을 조합한 지표이다.
- DCG보다 빠르지만 R-score metric보단 빠르지 않다.
$ARHR\left(u\right) = \sum_{j \in I_u} \frac{r_{uj}}{v_j}$
추천리스트의 사이즈 $L$을 고려하면 다음과 같은 식이 된다.
$ARHR\left(u\right) = \sum_{j \in I_u, v_j \lt L} \frac{r_{uj}}{v_j}$
Hit rate에 대해 먼저 알아보자면, 이는 테스트 세트의 모든 사용자에 대한 최고의 추천에 관한 모든 hit값을 합산하여 사용자 수로 나누어준 값이다.
ARHR은 보통 $|I_u|$ 의 값이 정확히 1이 되고, $I_u$ 집합에 속하는 hidden 아이템 j에 대한 평가값 $r_{uj}$이 1일 때 사용된다. 즉, 최상위 목록으로 추천을 잘 해주었는가를 따지는 값이 된다.
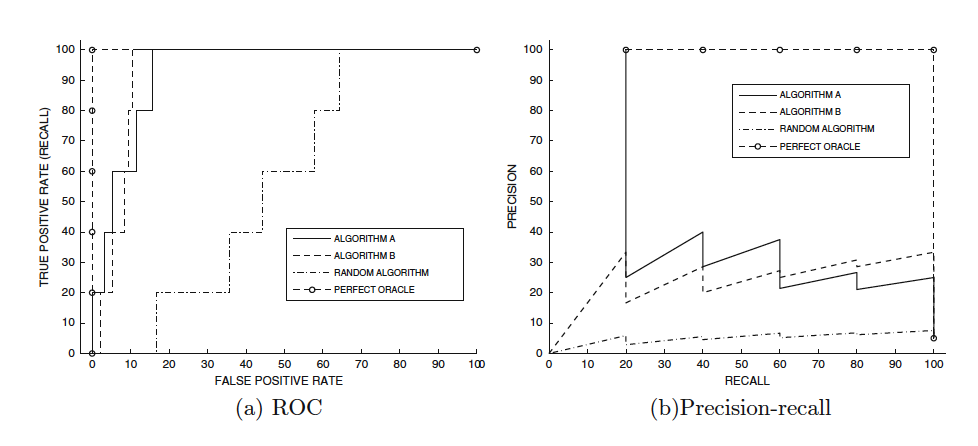
7.5.4 Evaluating Ranking via ROC
$\mathcal{S(t)}$ : 추천시스템이 추천한 항목의 집합(TP+FP)
$\mathcal{G}$ : 사용자가 소비한 항목의 집합(TP+FN)
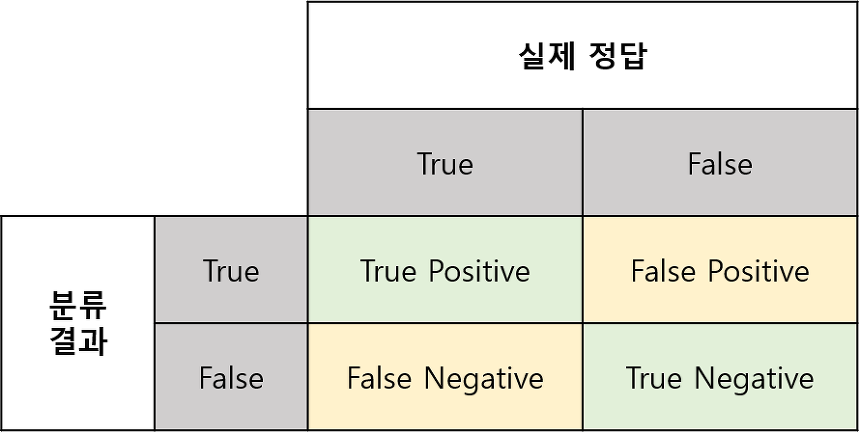
- TP : 추천시스템이 추천한 아이템을 사용자가 실제로 본 것
- FP : 추천시스템이 추천했지만 사용자가 보지 않은 것
- FN : 추천시스템이 추천하진 않았지만 사용자가 실제로 본 것
- TP + FP : 추천시스템이 추천한 항목
-
Precision : 실제로 사용자가 소비한 항목과 추천시스템이 추천한 항목의 교집합 개수 / 실제로 사용자가 소비한 항목의 개수 추천시스템이 추천한 것(모델이 True 라고 분류) 중에 실제로 사용자가 추천된 것을 본 비율
$Precision \left(t\right)= 100 \cdot \frac{|\mathcal{S(t)} \cap \mathcal{G}|}{|\mathcal{S(t)}|}$
$Precision \left(t\right)= \frac{TP}{TP+FP}$
-
Recall(hit rate, sensitivity) : 실제로 사용자가 소비한 항목과 추천시스템이 추천한 항목의 교집합 개수 / 추천시스템이 추천한 항목의 개수 사용자가 실제로 본 것(라벨이 True) 중에 실제로 사용자가 추천된 것을 본 비율
$Recall \left(t\right)= 100 \cdot \frac{|\mathcal{S(t)} \cap \mathcal{G}|}{|\mathcal{G}|}$
$Precision \left(t\right)= \frac{TP}{TP+FN}$
-
F1 score : Precision, Recall의 조화 평균
$F_1\left(t\right) = \frac{2 \cdot Precision\left(t\right) \cdot Recall\left(t\right)}{Precision\left(t\right) + Recall \left( t\right)}$
-
FPR : False-Positive rate
- $\mathcal{U}$ : the universe of all items
$FPR\left( t\right) = 100 \cdot \frac{|\mathcal{S(t)}-\mathcal{G}|}{|\mathcal{U}-\mathcal{G}|}$
7.6 Limitations of Evaluation Measures
Accuracy-based 평가 방법은 추첨시스템에서 selection 편향이 발생한다는 취약점이 있다. rating metrix에서 missing entries들은 랜덤하지 않은데 그 이유는 사용자들은 인기있는 항목에 평가하는 경향이 있기 때문이다.
we should expect to observe in many areas a difference between the distribution of ratings for random items and the corresponding distribution for the items selected by the users
이러한 요소들은 평가시에도 편향의 문제를 야기시킨다.
해결 방법
- missing rating을 랜덤하게 선택하지 않고 test rating을 선택하기 위한 모델을 사용한다.
- rating을 training, test를 랜덤하게 나누지 말고 더 최근의 데이터를 test set으로 나눈다. Netflix Prize Contest는 더 최근의 rating을 qulifying set으로 나눈다.
다른 한계는 사용자의 흥미가 시간에 따라 진화한다는 것이다. 결국 hold-out set은 미래의 취향을 반영하지 못한다. 완벽한 해결책은 아니더라도, training, test rating을 일시적으로 나누어 사용하는 것은 합리적인 선택이긴하다.