머신러닝의 주요 도전 과제
머신러닝의 주요 도전 과제
나쁜 데이터와 나쁜 알고리즘 이 머신 러닝에서 주요 해결해야 할 문제가 된다.
나쁜 데이터
충분하지 않은 양의 훈련 데이터
머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 한다.
믿을 수 없는 데이터의 효과 충분한 데이터를 주면 복잡한 문제는 쉬운 알고리즘에서 복잡한 알고리즘까지 비슷하게 성능을 낸다는 것이다. 시간과 돈을 알고리즘 개발에 쓰느냐 데이터 개발에 쓰느냐 사이의 트레이드오프에 대해 다시 생각해봐야 한다. 복잡한 문제에서 알고리즘보다 데이터가 더 중요하다. 하지만 좋은 데이터 세트를 구하는 일은 쉽거나 저렴하지 않기 때문에 알고리즘을 무시할 수는 없다.
대표성 없는 훈련 데이터
머신러닝 시스템이 좋은 예측이 가능하게 하려면 새로운 사례를 훈련 데이터가 잘 대표하는 것이 중요하다. 하지만 일반화하려는 사례들을 대표하는 훈련 세트를 항상 사용할 수는 없다. 샘플링 잡음sampling noise : 샘플이 작으면 발생한다. 샘플링 편향sampling bias : 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수 있다.
유명한 샘플링 편향 사례로는 1936년 미국 대통령 선거에서 시행한 대규모 여론 조사이다.
낮은 품질의 데이터
훈련 데이터가 에러, 이상치outlier, 잡음으로 가득한 경우이다. 이때 훈련 데이터를 다음과 같이 정제해야 한다.
- 일부 샘플이 이상치라는 게 명확하다면 간단히 그것을 무시하거나 수동으로 잘못된 것을 고치는 것이 좋다.
- 일부 샘플에 특성 몇 개가 빠져있다면, 이 특성을 모두 무시할지 이 샘플을 무시할지 빠진 값을 채울지 이 특성을 넣은 모델과 제외한 모델을 따로 훈련할 것인지
관련 없는 특성
garbage in, garbage out 엉터리가 들어가면 엉터리가 나온다.
성공적인 머신러닝을 위해서는 훈련 데이터가 훈련에 사용할 좋은 특성을 갖춰야 하는 것이다. 다음과 같이 특성 공학feature engineering 작업을 한다.
- 특성 선택 : 가지고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택한다.
- 특성 추출 : 특성을 결합하여 더 유용한 특성을 만든다.
- 새로운 데이터를 수집해서 새로운 특성을 만든다.
나쁜 알고리즘
훈련 데이터 과대 적합overfitting
과대 적합은 훈련 데이터에 있는 잡음의 양에 비해 모델이 너무 복잡할 때 일어난다. 쉽게 말하면, 특정 데이터 세트에만 적합 되어 새로운 샘플에 대해서 성능이 낮아지는 경우이다. 그래서 주어진 데이터 세트에 대해서는 오차가 없으므로 높은 성능을 보인다. 하지만 새로운 데이터 세트에 적용한다면 훈련 데이터와는 달리 큰 오차를 보인다. **<해결방법>**
- 파라미터 수가 적은 모델을 선택하거나 훈련 데이터에 있는 특성 수를 줄이거나 모델에 제약regulation을 가하여 단순화시킨다.
- 훈련 데이터를 더 많이 모은다.
- 훈련 데이터의 잡음을 줄인다.
규제regulation 모델을 단순하게 하고 과대 적합의 위험을 감소시키기 위해 모델에 제약을 가하는 것이다. 예를 들어 자유도degree of freedom을 학습 알고리즘에 부여하는 것이다. 데이터에 완벽히 맞추는 것과 일반화를 위해 단순한 모델을 유지하는 것 사이의 올바른 균형을 찾는 것이 좋다.
하이퍼파라미터 학습하는 동안 적용할 규제의 양은 하이퍼파라미터가 정한다. 하이퍼파라미터는 학습 알고리즘의 파라미터이다. 그래서 학습 알고리즘으로부터 영향을 받지 않으며, 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남아 있다. 하이퍼파라미터 튜닝은 머신러닝 시스템을 구축할 때 매우 중요한 과정이다.
훈련 데이터 과소 적합underfitting
모델이 너무 단순해서 데이터의 내재한 구조를 학습하지 못할 때 일어난다. 훈련 데이터와 테스트 데이터 모두 큰 오차를 보인다.
해결방법
- 모델 파라미터가 더 많은 강력한 모델을 선택한다. (복잡한 모델)
- 학습 알고리즘에 더 좋은 특성을 제공한다. (특성 공학) 데이터가 머신러닝으로 일반화하려는 사례들을 대표하고 있지 못하기 때문에 과소 적합이 일어날 수 있다.
- 모델의 제약을 줄인다. (규제 하이퍼파라미터를 감소시킨다) 하이퍼파라미터가 크게 적용하고 있어 학습이 잘 안 되는 것일 수도 있다.
편향-분산 트레이드오프
이상적으로 연구자는 편향과 분산 모두 작은 것을 원한다. 하지만 편향이 높을수록 분산은 작아지고 편향이 낮을수록 분산은 커지는 경향이 있다. 편향이 높다 : 예측값들이 정답으로부터 멀리 떨어져 있다. -> 주로 단순한 모델, 언더피팅 분산이 높다 : 예측값들이 흩어져있다. (정답과 가까운지는 상관없음) -> 주로 복잡한 모델, 오버피팅
둘 다 낮게 나오는 것이 좋다.
머신러닝 테스트와 검증
모델이 새로운 샘플에 얼마나 잘 일반화될 지를 알아야 한다. 그래서 모델을 새로운 샘플에 실제로 적용해보는 것이다.
테스트 세트
여차여차해서 모델을 구현했다. 실제 서비스에 모델을 넣었을 때도 충분한 성능을 갖췄을지 궁금할 것이다. 성능을 평가하는 지표는 일반화 오차를 구하는 것이다. 테스트 데이터는 모델이 실전에 배치되기 전에 새로운 샘플에 대해 만들 일반화 오차를 추정하기 위해 사용된다.
| 훈련 데이터 | 목적 |
|---|---|
| 훈련 세트 | 모델을 훈련한다. |
| 테스트 세트 | 모델을 테스트한다. |
- 일반화 오차 : 새로운 샘플에 대한 오류 비율, 일반화 오차로 이전에 본 적이 없는 새로운 샘플에 모델이 얼마나 잘 작동할지 알려준다.
검증 세트
모델 선택 문제 발생 !
-
두 모델 중 어떤 것을 선택할지 갈등하고 있다. 둘 중 하나를 어떻게 결정할 수 있을까? 두 모델 모두 훈련 세트로 훈련하고 테스트 세트를 사용해 얼마나 잘 일반화되는지 비교한다.
-
선형 모델이 더 잘 일반화되었다고 가정하자. 과대 적합을 피하고자(모델이 훈련 세트에 너무 잘 맞을 수 있으니) 규제를 적용하려고 한다. 하이퍼파라미터 값은 어떻게 선택할까? 100개의 하이퍼파라미터 값이 있다면 100개의 다른 모델을 훈련하면 된다. 그런데 이는 테스트 데이터에 100번의 다른 훈련을 적용한 것일까? 그래서 다음과 같은 오류가 생기는 것일까?
-
일반화 오차가 가장 낮은 모델을 만드는 최적의 하이퍼파라미터를 찾았다고 가정하자. 실제 서비스에 투입했다. 하지만 일반화 오차가 크다. 이유는? 일반화 오차를 테스트 세트에서 여러 번 측정했으므로 모델과 하이퍼파라미터가 테스트 세트에 최적화된 모델을 만들었고, 테스트 세트에 과대 적합 된 모델이 된 것이다. 이를 해결하기 위해 홀드 아웃 검증 방법을 사용한다.
홀드 아웃 검증 : 훈련 세트의 일부를 떼어내어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택한다. 이 새로운 홀드 아웃 세트를 검증 세트라고 한다.
사용 방법 :
- 전체 훈련 세트 - 검증 세트 한 데이터(B에서 주황색 training data)에서 다양한 하이퍼파라미터 값을 가진 여러 모델을 훈련한다. (하이퍼파라미터가 왜 여기에 나오지…?)
- 검증 세트에서 가장 높은 성능을 내는 모델을 선택한다. (-> 홀드 아웃 검증 과정)
- 이 모델을 전체 훈련 세트(검증 세트 포함)에서 다시 훈련하여 최종 모델을 만든다. (이 과정에서 하이퍼파라미터가 정해지는 건가?)
- 최종 모델을 테스트 세트에서 평가하여 일반화 오차를 추정한다.

교차 검증
훈련 세트에서 검증 세트를 여러 개로 나누어서 검증하는 것이다.
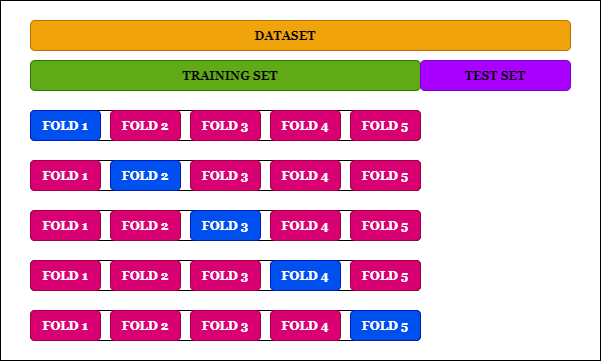 K-Fold Cross Validation for Deep Learning Models using Keras
K-Fold Cross Validation for Deep Learning Models using Keras
- 검증 세트가 너무 작으면 : 모델이 정확하게 평가될 수 없다. 검증 세트로 여러 모델 중 가장 성능이 좋은 모델을 선택해야 하는데 너무 작은 검증 세트로 선별된 모델이 좋은 모델일지 아닐지 알 수 없다.
- 검증 세트가 너무 크면 : 최종 모델은 전체 훈련 세트에서 훈련되는데 너무 작은 훈련 세트에서 훈련한 후보 모델을 비교하는 것은 적절하지 않다. 이를 해결하기 위해 반복적으로 교차 검증을 수행한다.
단점 훈련 시간이 검증 세트의 개수에 비례해 늘어난다.
훈련-개발 세트
데이터 불일치를 해결하는 방법이다. 데이터 불일치는 훈련 데이터의 일부를 떼어내어 또 다른 세트를 만드는 것이다.
데이터 불일치 : 검증 세트와 테스트 세트가 실전에서 기대하는 데이터를 가능한 한 잘 대표하지 못하는 경우. 따라서 검증 세트와 테스트 세트에 대표 사진이 배타적으로 포함되어야 한다.
공짜 점심 없음no free lunch 이론
어떤 모델이 최선인지 확실히 아는 방법은 모든 모델을 평가해보는 것뿐이다. 이는 인간인 우리는 불가능하다.